数据研究
同一个 IP,七个风控源给出七种答案
2026-06-20 · ipok.io
185.220.101.0 是一个德国的 Tor 出口节点。它的身份没有任何争议——它在公开的 Tor 共识列表里,任何人都能查到。把它丢进七个 IP 风控源里,你会看到这样一组分数(满分 100,越高越脏):
- ·proxycheck:100
- ·AbuseIPDB:100
- ·StopForumSpam:97
- ·ipapi.is:90
- ·IPOK-DB:90
- ·ip-api:85
- ·Scamalytics:0
六个源把它判成了核弹级风险,第七个源——Scamalytics——给了它满分的纯净度。一个已知的 Tor 出口,在某个商业风控接口眼里干净得像一台刚开机的家用宽带。
如果你的反爬、风控或者注册风控系统恰好只接了 Scamalytics 这一家,这个节点在你这里就畅通无阻;只接了 proxycheck,那它连 TCP 握手都不该有机会。同一个地址,同一次查询,结论完全相反。这不是个例,而是我接下来这套数据里反复出现的模式。
问题
做过风控、反爬、自建代理,或者只是想知道自己 VPS 出口 IP 干不干净的人,多半都查过 IP 纯净度。市面上一堆接口,每家都甩给你一个 0-100 的"风险值"。问题是:这些数字之间到底有多大分歧?分歧是随机噪声,还是有结构的?如果有结构,那结构本身能不能用?
方法
我采集了 109 个真实 IPv4 地址,可复现(seed=42),分四类:
- ·30 个 Tor 出口节点
- ·25 个 AWS 机房 IP
- ·14 个公共 DNS / anycast IP(比如那些人人都背得出的 resolver)
- ·40 个随机可路由 IPv4
采集只打了一个接口:ipok.io/api/ip。ipok 在服务端把多个源聚合好返回,所以我自始至终没有直接去碰 Scamalytics、proxycheck 这些家的接口——没有触发任何一家的 ToS,也没碰限速。返回里拆出 7 个风控源的独立打分:ip-api、proxycheck、ipapi.is、AbuseIPDB、IPOK-DB、StopForumSpam、Scamalytics。
是 7 个,不是 8 个,我数过。其中 IPOK-DB 是 ipok 自家的离线信誉库,这点必须摊开说,免得有人觉得我在偷偷塞私货。同一个 IP 的 7 个分数取自同一次查询,所以横向比的是同一时间点拿到的结果。
这里有个绕不开的前提:这 7 个源测的根本不是同一样东西。AbuseIPDB 和 StopForumSpam 是滥用举报历史库(这个 IP 被人举报过几次发垃圾、爆破);proxycheck 和 ipapi.is 主要做代理/VPN/机房识别;Scamalytics 给的是欺诈评分。它们各自定义的"风险"语义不同——这正是它们会分歧的一大原因,后面会展开。
发现一:同一个 IP 上的分歧是常态
把每个 IP 的 7 个源打分摊开看:
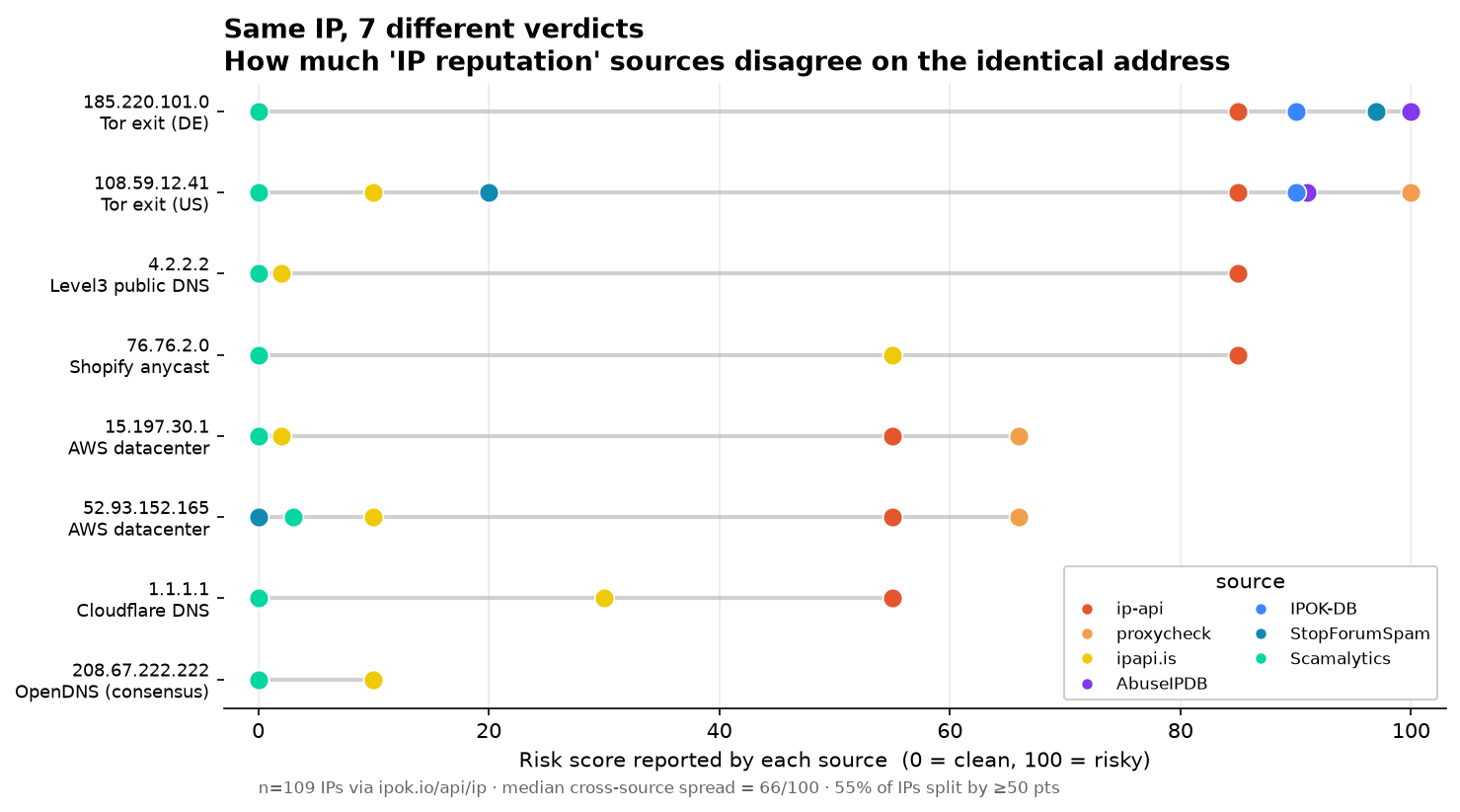
跨源分歧(同一 IP 上最高分减最低分)的中位数是 66/100,均值 48.5。说人话:典型情况下,对同一个地址,最乐观的源和最悲观的源差出去 66 分。55% 的 IP 上存在两个源相差 ≥50 分,27.5% 相差 ≥70 分。这不是小数点后的抖动,是结论级别的对立。
几个有代表性的例子:
4.2.2.2——Level3 的公共 DNS resolver,业内老熟人。ip-api 给了 85,其余每一家都在 0-2。聚合值落在 8。一个被全世界拿来当 DNS 测试的地址,被单独一个源判成了高危。无独有偶,Cloudflare 的 1.1.1.1 也是同一个剧本:ip-api 紧张兮兮,别家集体放行。
AWS 的 15.197.30.1:proxycheck 66、ip-api 55,而 Scamalytics、AbuseIPDB、IPOK-DB、StopForumSpam 全是 0,ipapi.is 给了 2。聚合 35。这是典型的"机房识别派"和"举报历史派"打架——它确实是机房 IP(所以 proxycheck 紧张),但它没有任何滥用历史(所以举报库都放行)。
发现二:分歧是有结构的,不是随机的
如果分歧纯属噪声,那它在各类 IP 上应该差不多。实际不是。按 IP 类型看平均分歧:
- ·Tor 出口:88
- ·机房 / hosting:52-63(hosting 这一档 63.1)
- ·商业 IP:48.5
- ·住宅 IP:21.2
- ·移动 IP:16.0
随机可路由那批整体 17.6。(住宅、移动这两档是在随机可路由样本内按 ipType 二次分类后算的均值,不是我单独抽的桶,所以没有独立的样本量可报。)
规律很干净:越是住宅、移动这种"原生"地址,各源越达成共识(分歧 16-21);越是 Tor、机房这种身份本就尴尬的地址,各源吵得越凶(分歧 52-88)。分歧不是系统坏了,分歧本身在告诉你这个 IP 的"成分"有多复杂、有多容易被不同标准判出不同结果。
反过来也有铁打的共识例。OpenDNS 的 208.67.222.222:所有源都在 0-10,分歧只有 10,聚合 2。所以这套方法不是"什么都互相打架"——该一致的时候它们高度一致,该打架的时候才打架。
发现三:每个源有系统性偏置
把 7 个源各自在这 109 个 IP 上的平均风险值拉出来:
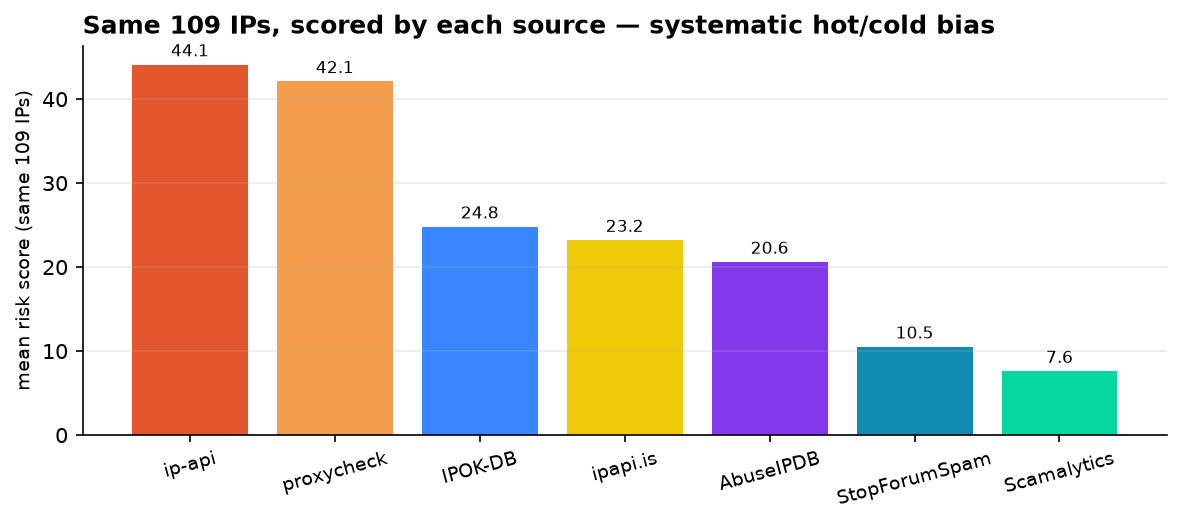
平均风险值(括号里是该源把 IP 判为 ≥50 的比例):
- ·ip-api:44.1(55%)
- ·proxycheck:42.1(49.5%)
- ·IPOK-DB:24.8(27.5%)
- ·ipapi.is:23.2(25.7%)
- ·AbuseIPDB:20.6(21.1%)
- ·StopForumSpam:10.5(8.3%)
- ·Scamalytics:7.6(3.7%)
ip-api 和 proxycheck 整体偏"热"——它们把将近一半的 IP 判成高风险。Scamalytics 和 StopForumSpam 整体偏"冷"——前者只对 3.7% 的 IP 拉警报。这跟它们的定位是自洽的:proxycheck 的工作就是逮机房和代理,自然对一大片 hosting 段开火;Scamalytics 做的是欺诈评分,只有真出过事的地址才会被它点名,于是连 Tor 出口都能给 0。
这也是为什么前面那个 Tor 节点会出现 0 和 100 并存:不是某家"错了",是它们各自只看自己那一面,而单独看任何一面都不够。
那凭什么七个源加一起就更可信?garbage × 7 还是 garbage?
这是最该被怼的一句话,我正面回答。
聚合的价值不在于把一堆噪声平均掉糊成一个数——那确实是 garbage × 7。它的价值在两件事上:
一、共识检测。 当几个口径不同、用不同信号搭起来的源对同一个地址给出接近的分数(住宅/移动那种 16-21 的低分歧),这个结论的置信度是很高的——它们从不同角度看都觉得这地址没问题。共识本身是信号。
二、把分歧暴露成"不确定性",而不是把它藏起来。 这是关键。当你只接一个源、它告诉你 185.220.101.0 是 0 分,你得到的是一个虚假的确定感——你以为它干净,其实是你瞎了一只眼。换成只接 proxycheck,你又会对一堆正常机房业务 IP 误杀。而当你同时看到 0 和 100 这种 88 分的撕裂,系统能诚实地告诉你:这个地址有争议,别拍板。
这里要直面一句最狠的反驳:你这共识论是循环论证——各源在住宅地址上一致,是因为住宅本来就好判,不是因为聚合有多聪明;真正难的 Tor 上,聚合只是继承了分歧,然后甩给"人工复核",等于在最该出力的地方什么都没加。这话说对了一半,但结论错了。在有争议的 IP 上,聚合确实变不出"正确答案",但它给的东西比"一个自信地报出来的错误答案"强得多:一个明确写着"这条别自动化"的标记。而单一源连"我自己也不确定"都说不出口。
还有第三点,前面已经埋了:因为这些源测的东西不一样(举报历史 + 代理识别 + 欺诈评分),把它们拼起来,覆盖的失效模式比任何单一源都多。一个只看举报历史的源会放过一个全新的、还没人举报过的纯机房代理;一个只看机房特征的源会冤枉一个正常的云上业务出口。两者叠加,互相补盲区。
顺带说一句"独立"这个词的水分:proxycheck 和 ipapi.is 都做代理/机房识别,用的信号高度重合(ASN、rDNS、已知段),在机房 IP 上它们其实算不上互相独立——fig2 里这俩也正好是最"热"的两家,均值咬得很死(44.1 / 42.1)。这种相关是预期之内的,不丢人,但正因如此,我说的是"用不同信号搭起来的源",而不是七个彼此独立的源。
诚实的局限
n=109 是个不大的样本,后面我会扩到 ~500,结论的强度会更高。Tor 出口和公共 DNS 在样本里是被"过采样"的——我故意挑了容易暴露分歧的硬骨头,所以中位数 66 这个数字对一般流量来说偏高,别拿它当你线上 IP 的预期分歧。
还有最该强调的那条:这 7 个源测的不是同一样东西。它们的分歧有一部分根本不是"谁对谁错",而是定义不同——拿欺诈评分去比代理识别,本来就不该相等。这是分歧的成因之一,理解了这点,你才知道该怎么读这些分数:不是找"哪家最准",而是看它们在一个地址上的组合形态。IPOK-DB 是 ipok 自家的库,我把它和外部源放在一起比,也一并把这个利益相关摊开。
给你的实操结论
别信任何单一的 IP 风控值。一个孤零零的 0 或 100 不构成证据。
要看就看多个源 + 它们之间的分歧(spread)。低分歧的低分 = 大概率真干净;低分歧的高分 = 大概率真脏;高分歧 = 这地址成分复杂,需要进一步看同段 /24、看 ASN、看它实际承载什么业务,而不是直接信某一家。判机房、判 Tor、判代理出口,尤其要这么看——它们正是分歧最大的那批。
这份数据集是用 ipok.io 跑出来的,用 seed=42 可复现——它会把每个源对每个 IP 的独立打分都列出来。想自己复现或拿去查自己出口 IP 的,免费、不用登录:npx ipok-cli、pip install ipok,或直接上 ipok.io。