Data study
One Tor Exit, Seven Verdicts: Why a Single IP-Reputation Score Lies to You
2026-06-20 · ipok.io
185.220.101.0 is a Tor exit node in Germany. It has been one for years. If you run a forum, a checkout flow, or an SSH endpoint, this is exactly the kind of address you'd want flagged.
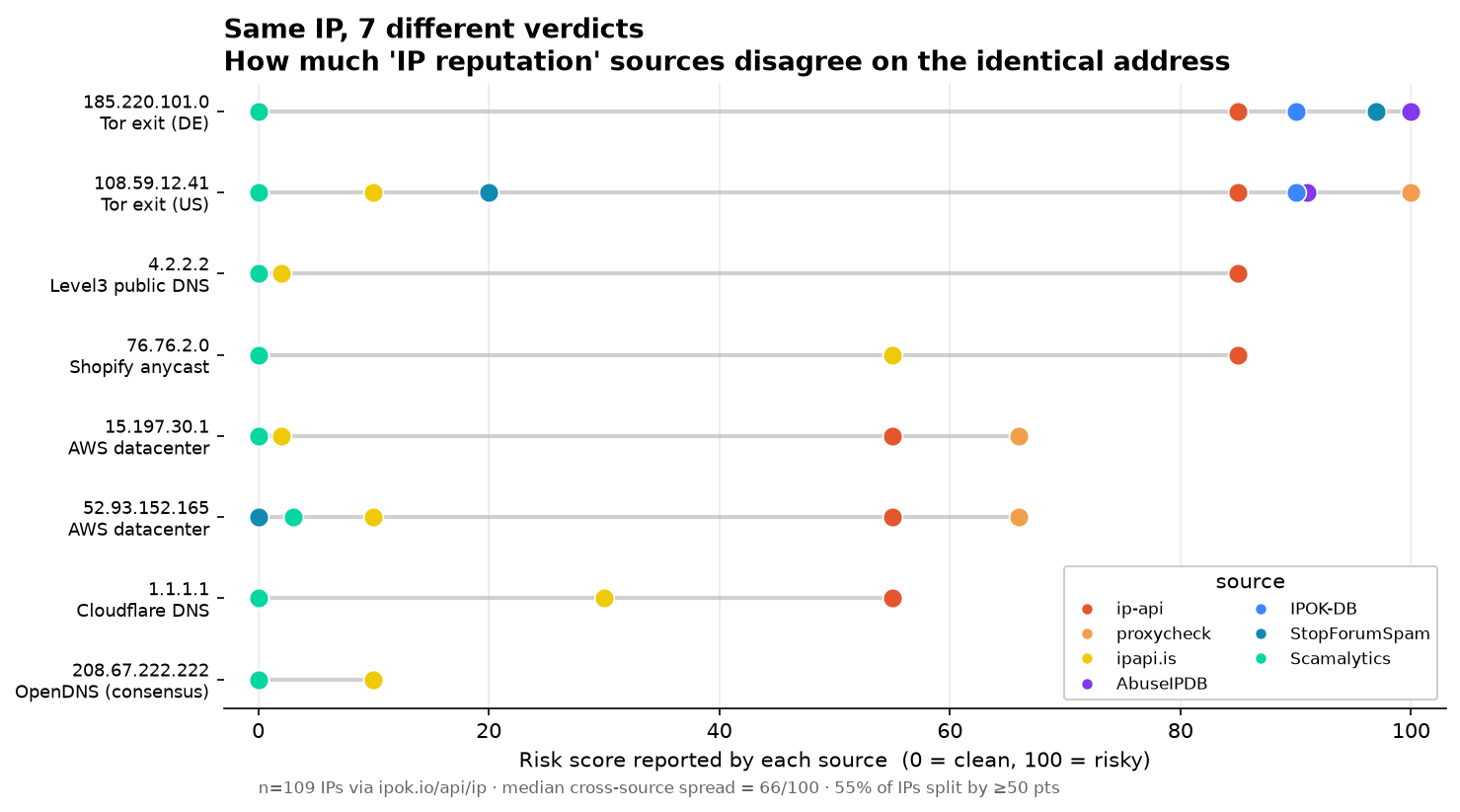
So I asked seven IP-reputation sources what they thought of it. proxycheck said 100. AbuseIPDB said 100. StopForumSpam said 97. ipapi.is said 90. ipok's own offline database said 90. ip-api said 85. And Scamalytics said 0 — pristine, nothing to see here.
Same address. A 100-point spread between two commercial reputation providers, on an IP whose status is not even ambiguous. If your fraud rule happened to read Scamalytics, a textbook Tor exit sailed through clean. If it read proxycheck, the same packet hit a wall. Six of the seven sources called it dangerous; one waved it through. That single fork is the whole problem in miniature.
The question
The pitch for any IP-reputation API is that it hands you a number and you act on it: block above 75, challenge above 50, allow below. The implicit promise is that the number means something stable — that "this IP is risky" is a property of the IP, not of the vendor you happened to query.
I wanted to know how often that promise holds. Not anecdotally — measured, across address types that matter to anyone running infrastructure.
The method
I scored 109 real IPv4 addresses against 7 sources and looked at where they agreed and where they didn't.
The sources are ip-api, proxycheck, ipapi.is, AbuseIPDB, IPOK-DB, StopForumSpam, and Scamalytics. One of those — IPOK-DB — is ipok's own offline reputation database, so I have a stake in one of the seven datapoints; I'm calling that out up front rather than after the conclusion.
I did not hit seven APIs directly. I queried a single endpoint, ipok.io/api/ip, which aggregates these sources server-side and returns each one's score alongside its own blended figure. That sidesteps seven separate rate limits and seven separate terms of service, and it means every source's score for a given IP comes from the same query. The 109 addresses break down into 30 Tor exit nodes, 25 AWS datacenter IPs, 14 public-DNS / anycast resolvers, and 40 randomly sampled routable IPv4. The whole thing is reproducible with seed=42.
One caveat I'll keep repeating because it matters: these sources do not measure the same thing. AbuseIPDB and StopForumSpam are abuse-report ledgers — did someone complain about this IP. proxycheck and ipapi.is are proxy/VPN/hosting detectors — is this address infrastructure rather than a human's home connection. Scamalytics is a fraud score. ip-api blends geo and network metadata. Asking all of them for "the risk" and expecting one answer is a category error, which is a big reason the numbers scatter.
What the data shows
1. They disagree, a lot, and predictably.
Across the 109 IPs, the median spread between the highest and lowest source on a single address is 66 out of 100. The mean is 48.5. More than half the sample — 55% — has at least two sources differing by 50 points or more; 27.5% differ by 70 or more. This isn't a handful of edge cases dragging an average around — it's the middle of the distribution.
The disagreement is structured, not noise. Sort the spread by address type and a clean gradient appears: Tor exits scatter most (mean spread 88), hosting and datacenter IPs next (52–63; hosting specifically 63.1), business ranges 48.5, and then it collapses — residential 21.2, mobile 16.0. (Those residential and mobile figures are means over IPs classified by type within the random-routable sample, not separate buckets I drew on purpose; the random-routable sample as a whole sits at 17.6.)
In other words: sources agree on boring addresses and fight over interesting ones. A home DSL line looks clean to everybody. A Tor exit looks like a maximum threat to six sources and a clean bill of health to one. The disagreement concentrates exactly where you most need a correct answer.
2. Each source has a fixed temperament.
Average each source's score over the same 109 IPs and they line up from hot to cold:
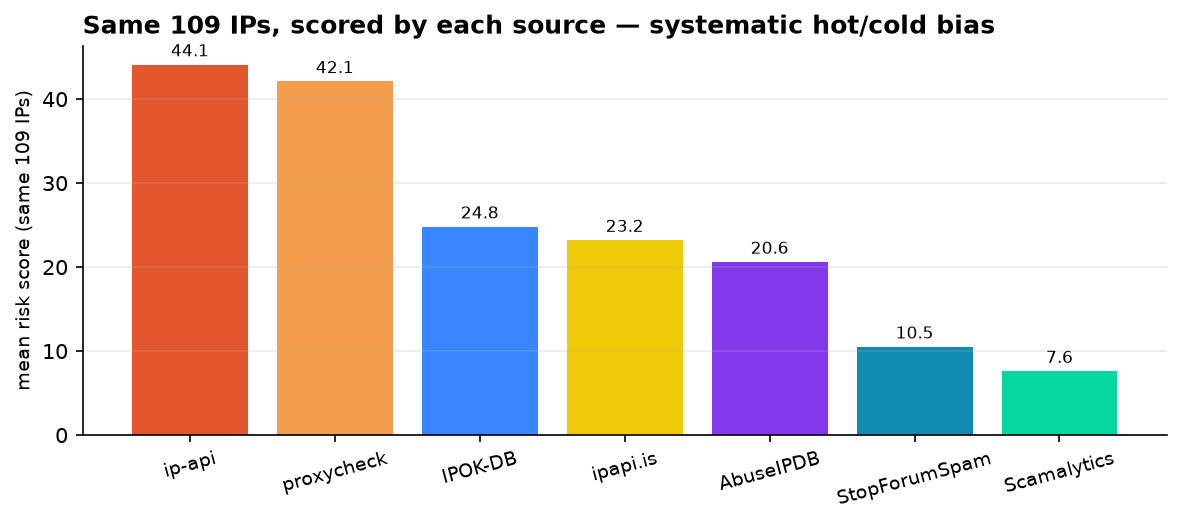
ip-api averages 44.1 and flags 55% of all IPs at 50-or-higher. proxycheck is right behind at 42.1 (49.5%). At the other end, StopForumSpam averages 10.5 (flags 8.3%) and Scamalytics averages 7.6 (flags just 3.7%). That isn't 109 independent coin flips landing differently — it's a systematic offset. ip-api and proxycheck run hot; they'll call infrastructure risky on sight. Scamalytics and StopForumSpam run cold; they want an actual fraud or abuse signal before they'll move off zero.
Which is defensible for each of them given what they measure — a proxy detector should light up on hosting ranges, an abuse ledger shouldn't without a report. But it means the threshold you tuned against one source is meaningless against another. "Block above 50" blocks half your traffic on ip-api and almost none of it on Scamalytics.
3. The non-Tor cases tell the same story.
4.2.2.2 is Level3's public DNS resolver — one of the most recognizable addresses on the internet. ip-api scored it 85; every other source scored it 0 to 2. 1.1.1.1, Cloudflare's resolver, is the same shape: ip-api 55, everyone else flat at 0 — one source decides a globally famous resolver is moderately risky while the rest don't blink. The hot source isn't reacting to abuse; it's reacting to the kind of address.
Datacenter and anycast space repeat the pattern. On the AWS address 15.197.30.1, proxycheck said 66 and ip-api 55, while Scamalytics, AbuseIPDB, IPOK-DB and StopForumSpam all said 0 and ipapi.is said 2. Shopify's anycast 76.76.2.0 and the AWS IP 52.93.152.165 split the same way — the proxy/hosting detectors and ip-api flag infrastructure on sight; the abuse and fraud sources, seeing no complaints, stay near zero. Even the US Tor exit 108.59.12.41 fractures across the full range: proxycheck and AbuseIPDB at the top, ipapi.is and StopForumSpam down at 10–20.
You might expect everything to disagree about everything, but it doesn't. 208.67.222.222 is OpenDNS. Every source put it between 0 and 10 — total spread of 10 points, aggregate 2. When an address is genuinely, unambiguously clean, the sources converge. The spread itself carries information.
"So why is averaging seven noisy numbers any better than one?"
This is the obvious objection, and it deserves a straight answer. If single sources are unreliable, blending seven of them sounds like averaging garbage into more garbage.
It would be, if the move were "take the mean and trust it." It isn't. The value is in two things the spread gives you that a single number can't.
First, consensus is a confidence signal. When seven differently-built sources — measuring different things, with different temperaments — all land near zero on OpenDNS, that agreement is meaningful. Clean residential and mobile addresses show mean spreads of 16–21 precisely because everything lines up. Tight spread, high confidence. A single source can't give you that, because it has nothing to agree with.
It's worth being honest about what "differently-built" does and doesn't buy you. proxycheck and ipapi.is are both proxy/hosting detectors working off overlapping signals — ASN, rDNS, known ranges — and the chart shows them as the two hottest sources, nearly tied at 44.1 and 42.1. On datacenter IPs they are not really independent, and that's fine: two detectors of the same failure mode correlating is expected, not a flaw. The triangulation comes from combining different failure modes, not from pretending every source is a fresh opinion.
Second, and more important, disagreement is the output, not a bug to smooth away. On 185.220.101.0, a single source hands you false confidence in one of two directions: query Scamalytics and you're confidently wrong that it's clean; query proxycheck and you're confidently right but you don't know how fragile that verdict is. Surface all seven and the 0-to-100 spread tells you the real state of the world: this address is contested, dig deeper.
And here's the sharpest version of the objection, the one worth meeting head-on: consensus is circular — sources agree on residential because residential is easy, and on the hard cases the aggregate just inherits the disagreement and punts to manual review, so it adds nothing where it matters. Yes — on a contested IP the aggregate doesn't magically produce the right answer. It produces something better than a wrong answer delivered confidently: a flag that says don't automate this one. A single source can't even tell you it's uncertain.
The third reason is the one from the caveat. Because the sources cover different failure modes — abuse history, proxy/hosting detection, fraud scoring — combining them covers more ground than any one alone. A fresh Tor exit with no abuse reports yet is invisible to AbuseIPDB but obvious to a proxy detector. A compromised residential IP spewing spam is invisible to a proxy detector but lights up StopForumSpam. The union catches what each one misses. The point of seven sources isn't to vote; it's to triangulate.
Limits
n=109 is a modest sample. It's enough to make the structure visible — the per-type gradient and per-source bias are not subtle — but I'd want it at ~500 before quoting any of these means to a second decimal. The address mix is also deliberately adversarial: I oversampled Tor and datacenter space because that's where the action is, so the headline median spread of 66 is higher than you'd see on a random slice of live web traffic. And, again, IPOK-DB is ipok's own source; treat it as one input among seven, not a neutral referee.
What to actually do
Never act on a single IP-reputation number. Not because any one source is worthless — each is reasonable within what it measures — but because no single one knows what it doesn't know. Pull at least two or three sources that measure different things (one abuse ledger, one proxy detector, one fraud score), and watch the spread as carefully as the value. Tight spread near zero: clean, ship it. Tight spread near 100: blocked, done. Wide spread: contested — route it to a challenge, a manual review, or a second factor instead of pretending a number settled it.
The dataset behind this came from ipok.io, which shows every source's score per IP. If you want to poke at your own addresses the way I did here, it's npx ipok-cli <ip> or pip install ipok — free, no login — or just the site. Reproduce the study with seed=42.